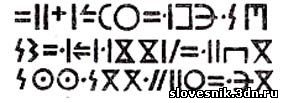ПОКА НЕ РАЗГАДАНЫ
 а
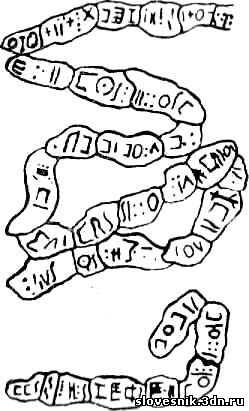
скалах в Сахаре, помимо рисуночных изображений, самыми известными из
которых являются фрески Тассили, можно увидеть и странные «ленты»,
процарапанные но камню, внутри которых находятся значки, похожие на
рунические, с добавлением точек, кружков, «крестиков». От этих надписей
веет глубочайшей древностью. Каково же было удивление ученых, когда они
обнаружили, что подобным письмом и по сей день пользуются покорители
Сахары, — туареги. Причем сохранилось оно только у женщин (мужчины, как
правоверные мусульмане, пользуются арабским письмом). «Женское письмо
туарегов» называется ими самими тифинаг. Лингвисты без труда узнали в
этом слове вариант латинского «пуника» — так называли карфагенян древние
римляне. А грамматологи обнаружили несомненное сходство знаков письма
тифинаг с древнейшими надписями из Туниса и Алжира, возраст которых
около двух тысяч лет. Письмена эти принято называть ливийскими или
нумидийскими (по наименованию Нумидии, древнего государства,
существовавшего на территории нынешнего Магриба). а
скалах в Сахаре, помимо рисуночных изображений, самыми известными из
которых являются фрески Тассили, можно увидеть и странные «ленты»,
процарапанные но камню, внутри которых находятся значки, похожие на
рунические, с добавлением точек, кружков, «крестиков». От этих надписей
веет глубочайшей древностью. Каково же было удивление ученых, когда они
обнаружили, что подобным письмом и по сей день пользуются покорители
Сахары, — туареги. Причем сохранилось оно только у женщин (мужчины, как
правоверные мусульмане, пользуются арабским письмом). «Женское письмо
туарегов» называется ими самими тифинаг. Лингвисты без труда узнали в
этом слове вариант латинского «пуника» — так называли карфагенян древние
римляне. А грамматологи обнаружили несомненное сходство знаков письма
тифинаг с древнейшими надписями из Туниса и Алжира, возраст которых
около двух тысяч лет. Письмена эти принято называть ливийскими или
нумидийскими (по наименованию Нумидии, древнего государства,
существовавшего на территории нынешнего Магриба).
Нумидийские письмена — предтеча современной
письменности туарегов. Откуда произошли они, до сих пор неясно. Название
«тифинаг» указывает на пуническое письмо, ветвь финикийского. Однако
знаки тифинага совершенно не похожи на финикийские. Назывались и другие
«адреса»: Южная Аравия, Египет, Синайский полуостров, Эгеида. Но все
это — лишь гипотезы. Тем более, что не расшифрованы тексты, найдсииые в
Мавритании; мы можем читать лишь письмена Магриба.
Нерасшифрованными остаются и так называемые
турдетанские письмена, которые нашли на территории Южной Испании, где
некогда существовало могущественное государство Тартесс, о богатстве
которого можно найти упоминания даже в Библии (сюда, за серебром и
другими ценностями, посылал свои корабли царь Соломон). Целый ряд
турдетанских знаков похож на знаки нумидийцев и ливийцев. Другие знаки,
напротив, обнаруживают сходство с письменами, найденными здесь же, на
Пиренейском полуострове, которые также не расшифрованы (их называют
иберийскими, от древнего названия Испании — Иберия). И, что самое
интересное, есть большое сходство между иберийскими и карийскими
письменами, хотя их разделяет Средиземное море.
В Малой Азии совсем недавно был обнаружен ряд
текстов, написанных письменами, похожими на карийский алфавит, но тем не
менее, отличными от него. Одни из них называют паракарийскими
(«околокарийские»), другие — кароидными («подобные карийским»). Найдены и
тексты, похожие на лидийские письмена (паралидийские). Все они не
расшифрованы (да и карийские тексты мы научились читать каких-нибудь 7–8
лет назад), и, возможно, раскрытие тайны этих письмен прольет свет и на
многие спорные вопросы происхождения и распространения алфавита. Ведь
не исключено, что и греки, и финикийцы, и жители Малой Азии и жители
Южной Аравии позаимствовали свои знаки из одного и того же источника,
«протофиникийского» письма, памятники которого пока что не удалось
обнаружить. Туарегское письмо тифинаг.
А помимо этих нерасшифрованных алфавитов (да и
алфавитов ли?), непрочтенными остаются надписи, покрывающие скалы
Канарских островов, протоурартские иероглифы и Майкопская плита,
найденпые на Кавказе, краткие тексты, вроде диска из Феста, надписи на
камнях в районе Анд или надписи на сосуде из Алеканово, и длинные
тексты, оставленные индейцами майя, протоиндийские и критские рисуночные
письмена, слоговая письменность Библа, кохау ронго-ронго острова Пасхи,
различные «протописьмена», обнаруженные на территории Египта,
Синайского полуострова, Палестины, Сирии, письмена бохайцев, киданей,
чжурчжэней на Дальнем Востоке и загадочные геометрические знаки,
покрывающие более пятисот сланцевых плит, найденных в различных частях
Испании.
«РАССТОЯНИЕ ЕДИНСТВЕННОСТИ»
Перед нами «текст», состоящий из одного единственного
знака. Можно ли расшифровать его? Разумеется, нельзя. Ведь знак может
быть, в принципе, любой буквой неизвестного алфавита. И не только
буквой, но и слоговым знаком, или логограммой, или идеограммой.
А если текст состоит из 10 знаков? 100? 1000? 10 000?
Когда мы можем решить, что объем текста достаточен для его дешифровки?
Первую попытку ответить на этот вопрос предпринял американский инженер и
математик Клод Шеннон, создатель теории информации.
В годы второй мировой войны остро стоял вопрос о
создании надежных шифров. Необходимо было решить и противоположную
задачу: расшифровывать секретные донесения противника. В Соединенных
Штатах над решением этой проблемы работали многие выдающиеся ученые, в
том числе и Клод Шеннон. Результатом его исследований стал секретный
доклад «Математическая теория криптографии» (тайнописи). После окончания
войны доклад был рассекречен и лег в основу работы Шеннона «Теория
связи в секретных системах», перевод которой был опубликован и в вашей
стране. Нумидийская надпись.
«Расстояние единственности» — так назывался в этой
работе минимальный объем текста, при котором возможно одно, единственно
правильное, «решение», расшифровка криптограммы. Допустим, мы имеем
шифровку на английском языке, где буквы заменены цифрами (вспомните
«Золотого жука» Эдгара По, который, кстати, был одним из пионеров
математической методики расшифровки криптограмм). В принципе, мы можем
прочитать эту (и любую другую) шифровку путем простого перебора. Имеется
26 различных цифр. Им соответствует 26 букв английского алфавита.
Последовательно пробуя варианты (является ли знак 01 буквой «а»? буквой
«в»? буквой «с»? и т. д.), мы можем натолкнуться на верное решение. Но
оно будет единственно правильным лишь тогда, когда нам в руки попал
достаточно большой текст. В противном случае мы можем прочесть шифровку
несколькими способами. И все они будут правильны с точки зрения
английского языка, все они будут составлять осмысленные тексты.
Шеннон показал, что для английского языка и алфавита
«расстояние единственности» равно примерно тридцати знакам. Если мы
имеем текст такой (или большей) длины, мы вправе считать, что он имеет
одно и только одно «решение». Если длина текста меньше тридцати знаков,
возможно несколько его «прочтений». И чем короче текст, тем больше
вариантов «прочтения» он допускает.
Например, если в тексте всего лишь восемь знаков, мы
можем сопоставить с ним более 40 000 комбинаций английских букв, которые
могут соответствовать этим знакам. Примерно 1/8
этих комбинаций будет правильной, т. е. будет образовывать слова
английского языка. Иными словами, возможно около 5000 «решений»
криптограммы (т. е. эти восемь знаков могут быть прочтены и как слово
the first, и как district, и как in danger и т. д. и т. п.). А это
говорит о том, что практически мы не в состоянии расшифровать
криптограмму — слишком уж много вариантов ее решения, слишком уж мало
знаков входит в нее.
Как же Шеннону удалось определить «расстояние
единственности», величину текста, достаточного для дешифровки? Величина
эта слагается на трех показателей. Прежде всего — общее число разных
знаков, чтение которых нам предстоит установить. Затем — число
«референтов», количество букв (или звуков), которым должны
соответствовать знаки шифровки (например, в случае, разбиравшемся выше,
число цифр-знаков равно 26, число «референтов», букв английского
алфавита, также равно 26). И, наконец, необходимо знать третью
величину, — так называемую «избыточность языка».
Не всякое сочетание букв образует английское слово
(так же, как русское, немецкое и т. д.). Одни буквы и сочетания букв
употребляются в английском очень часто (например, «ти-эйч»), другие —
редко, а третьи по встречаются вообще (например «эйч-ти»). Кроме законов
фонетики, морфологии, лексики, есть еще и законы грамматики, требующие
согласования времен, падежей и т. д. Все это накладывает на язык
множество «запретов», ограничений. И тем самым создает «избыточность»
языка (если есть местоимение «мы», то и глагол будет во множественном
числе и т. д.). Для английского языка она равна примерно 75 процентам.
То есть примерно три четверти букв в английском тексте являются
«липшими», появление их вызвано не стремлением передать информацию, а
законами грамматики, лексики и т. д. Конечно, это сокращает во много раз
число возможных сообщений и позволяет находить «расстояние
единственности» для криптограмм.
ФОРМУЛЫ ТИПОВ ПИСЬМА
Возможно ли применить методику Шеннона к древним
текстам? Разумеется, все исходные величины — и число дешифруемых знаков,
и число их возможных «референтов», и величина избыточности — будут
иными. Но общий подход остается тем же. Справедливой остается и формула,
по которой определяется «расстояние единственности», объем текста, при
котором возможна его однозначная расшифровка.
Лингвисты определили величину избыточности в самых
разных языках мира: в русском и армянском, немецком и азербайджанском,
самоанском и румынском. И везде она колеблется в пределах 70–80
процентов, т. е. в любом тексте, записанном буквами около трех четвертей
этих букв — «лишние», они диктуются законами языка. Меньше всего
различных букв в гавайском алфавите — всего лишь 12 согласных и 7
гласных. Больше всего букв и в алфавитах, разработанных советскими
языковедами для языков Кавказа — свыше пятидесяти. Нетрудно определить и
число возможных «референтов» знаков любого алфавита, которыми будут
звуки языка. Меньше всего их в языке аранта, одного из австралийских
племен — всего десять звуков, десять фонем. Больше всего — в тех же
языках Кавказа (до восьмидесяти фонем!).
Зная эти цифры, нетрудно определить, какой величины
должен быть алфавитный текст, чтобы мы могли дать его однозначную
дешифровку. Для гавайского алфавита получаем 20 букв, для русского — 70,
армянского — 80. Допустим, мы встретились с самым трудным случаем,
когда текст написан на каком-то из кавказских языков, где может быть до
80 звуков «референтов», а число неизвестных знаков письма превышает 50,
как в нерасшифрованном агванском письме. Величина «расстояния
единственности» будет равна здесь 200 знакам, в десять раз превышая
величину для гавайского алфавита. Но это — предел. Значит, если в нашем
распоряжении есть текст, записанный нерасшифрованным алфавитом, и его
объем равен 200 и более знакам, можно с уверенностью утверждать:
дешифровка этого текста возможна, ибо она имеет только одно «решение»,
текст можно прочесть только одним способом.
Но ведь исследователям приходится иметь дело не
только и не столько с алфавитами, но и со слоговыми и смешанными,
словесно-слоговыми системами письма, а также логографическими
письменностями, типа тангутской или китайской.
Определить число разных знаков в системе письма
нетрудно. Можно рассчитать, скольким слогам или словам должны
соответствовать эти знаки. Гораздо трудней вычислить величину
«избыточности» для древних письменностей. Но и эта задача разрешима.
Для логографического (знак-слово) письма избыточность
равна примерно 50 процентам, Это означает, что «липшими» в тексте,
написанном логограммами, будет половина всех знаков. Логография
оказывается гораздо более экономным письмом, чем алфавит (правда, эта
экономия достигается дорогой ценой, сравните несколько десятков знаков в
алфавитах и тысячи и тысячи знаков-логограмм в китайском и тангутском
письме). Для того чтобы однозначно расшифровать текст, записанный
знаками-логограммами, он должен быть очень большим, порядка миллиона
знаков.
Величина избыточности слогового письма находится
где-то между величинами алфавита и логографии (слоговое письмо более
«ёмко», чем буквенное, но менее «ёмко», чем логографическое), т. е.
между 50 и 70 процентами. В среднем можно принять величину, равную 60
процентам. Для определения числа «референтов» слоговых знаков нужно
принимать во внимание тип слогового письма. Если все знаки передают лишь
открытые слоги («гласный» и «согласный + гласный»), их будет гораздо
меньше, чем в случае употребления открытых и закрытых слогов. От этого
зависит и величина «расстояния единственности». Для силлабариев первого
типа она будет равна примерно 300–500 знакам, для второго — порядка 5–8
тысяч знаков (ведь и число возможных слогов в них измеряется многими и
многими сотнями!).
Словесно-слоговое письмо состоит из знаков двух
типов. «Смешанным» будет и способ определения объема текста: нужно
рассчитать «расстояние единственности» отдельно для слоговых и отдельно
для логографических знаков, а затем полученные величины сложить. Для
иероглифики типа египетской (где 24 одногласных «алфавитных» знака и
около 700 логограмм) получаем величину в 6000 знаков для письма типа
«хеттской иероглифики» (60 слоговых знаков, передающих открытые слоги и
около 400–450 логограмм) также 6000 знаков. Для шумерской и аккадской
клинописи получаем величину порядка 15 000—20 000 знаков (ибо здесь
гораздо больше слоговых знаков, а они могут иметь большее число
«референтов» как открытых, так и закрытых слогов).
ЗНАКИ И ЧИСЛА
Таким образом, мы получаем, с помощью математической
статистики и теории информации, надежную «точку опоры». Зная тип
недешифроваиного письма (алфавит, силлабарий и т. д.), мы можем
сравнивать объем текста, написанного этим письмом, с величиной
«расстояния единственности» и сразу же узнать, достаточен ли такой текст
для однозначной дешифровки или нет.
Протобиблские письмена, как говорилось выше, написаны
слоговым письмом, передающим только открытые слоги. «Расстояние
единственности» для силлабариев такого типа — порядка 300 знаков. Общее
же число знаков в протобиблских текстах 1000. Значит, дешифровка их
возможна, ибо существует единственное «решение», один правильный способ
прочтения протобиблских слоговых знаков.
А вот второй образец текста, написанного письмом
подобного же типа, — диск из Феста. Общее число знаков в нем 241. Это —
меньше, чем «расстояние единственности», равное тремстам знакам. Значит,
как бы убедительно ни читалась надпись, возможны и другие варианты ее
прочтения, другие — столь же правильного «решения». Иными словами,
однозначная дешифровка этого уникального памятника невозможна.
Мы не будем рассказывать о том, как методы математики
применяются для определения типа письма, которым написан неразгаданный
текст, как выявляется формула «языка икс» и сопоставляется с «формулами»
других языков, в поисках родственного наречия, которое могло бы стать
«ключом» в дешифровке. Остановимся на другом — на исторической смене
«интереса» в дешифровках древних письменностей.
Вначале этот «интерес» был направится на содержание
древних текстов, будь это египетская иероглифика или клинописные тексты
Двуречья. Но вот эти тексты — юридические, исторические, хозяйственные,
поэтические и т. д. — были в основном, прочтены. Нерасшифрованными
остались скудные и отрывочные тексты народов и государств, о которых
дошли лишь упоминания в древних хрониках, а порой о них вообще ничего не
было известно. Большинство подобных письмен также дешифровано. Но
содержания текстов мало что дало историкам древнего мира. Гораздо более
ценные сведения почерпнули они от языковой принадлежности этих текстов.
Оказалось, что таинственные письмена, найденные на острове Крит и в
Греции (линейное письмо Б), написаны на греческом языке. Между тем до
этого считалось, что греки появились здесь по крайней мере спустя
800–1000 лет! Загадочный народ, хетты, оказался по языку родствен другим
народам, говорящим на индоевропейских языках.
В середине нашего столетия наметилось новое
«смещение» интереса в дешифровке. Теперь исследователей интересует не
только и не столько содержание текстов, оставшихся нерасшифрованными, и
даже не их языковая принадлежность, сколько сами методы дешифровки.
Причины здесь две — внешняя и внутренняя. Сейчас
полнились новые области пауки, которые неразрывно связаны с теорией
дешифровки: это и семиотика, наука о знаках, и теория информации, и
кибернетика, и многие другие дисциплины. Но еще более важны внутренние
причины. Дело в том, что дешифровки прошлого были проведены с помощью
билингвы. Наряду с текстом, который предстояло расшифровать, имелся
параллельный текст, написанный на известном языке известными знаками.
Он-то и давал дешифровщикам прошлого надежную «точку опоры». А все
оставшиеся к нашему времени непрочтенными древние тексты подобной «точки
опоры» — билингвы — не имеют. И чтобы расшифровать их, необходимо
изучать саму структуру текста, внутренние закономерности языка,
частотность знаков и т. п.
Чтобы наши выводы относительно неизвестного текста
были достоверны, нужно изучать и структуру текстов известных, выводить
общие закономерности письма, распределения знаков по частоте и позициям в
буквенном, слоговом и других типах письменности. Словом, отыскивать
всеобщие, универсальные законы и, исходя из них, трактовать неизвестное
через известное. Таким образом, дешифровка текстов становится
неотъемлемой частью грамматологии, изучающей законы письма, его
универсалии. О поисках универсалий и пойдет речь в следующей главе.
|

 УЧИТЕЛЬ СЛОВЕСНОСТИ
УЧИТЕЛЬ СЛОВЕСНОСТИ