Читали ли вы увлекательный (особенно в те дни, когда вы были ребенком) рассказ Эдгара По «Золотой жук»?
Напомнить его содержание, видимо, всё же придётся.
Разорившийся богач, франко-американец, находит в
песке на океанском берегу Северной Америки клочок пергамента. Случайно
нагрев его, он заметил изображения — черепа и козлёнка — в разных углах
куска кожи.
Этот Легран — человек логического ума. Он быстро
догадывается, что перед ним написанная симпатическими чернилами записка
пирата (череп) Кидда («кидд» — козленок). Проявив остальной текст более
энергичным подогреванием, Легран видит запись, состоящую из тайных
значков.
К удивлению своего туповатого друга-рассказчика
(точь-в-точь доктор Ватсон Конан-Дойля), этот Шерлок Холмс начала XIX
века, потрудясь, прочитывает непонятную записку и отправляется с верным
слугой-негром и этим своим другом в дикие заросли холмистого побережья,
где находит клад капитана Кидда, спрятанный в земле лет двести или
триста назад.
Ему приходится объяснять потрясенному другу, как он
дошел до истины. Тут-то и оказывается, что помог ему осуществить это
«закон букв». Как же воспользовался им он?
Найдя непонятные знаки, Легран заметил: не все они
одинаково часто встречаются в грамотке. Чаще всего попадался значок в
виде цифры 8. Почему? Раскинув умом, Легран вспомнил: в английской
письменной речи самая часто встречающаяся буква — Е. Значит, можно допустить, раз автор — Кидд и документ должен быть написан по-английски, что восьмерка и есть Е.
Попались ему и две-три пары восьмерок, значит, все 88 надо записать как ЕЕ.
Раз так, ясно стало ещё одно существенное
обстоятельство. Перед половиной английских существительных стоит
определенный артикль — THE. Значит, там, где встречается слово из трех
знаков с 8 на конце, это THE. Тогда и два других знака должны совпадать.
Так и есть: много раз повторялись «точка с запятой», «четвёрка»,
«восьмёрка». Легран теперь узнал уже значение трёх разных букв! Началось
же все с немногого: со знания, что буква Е встречается в английском языке чаще других букв. Таков закон этой буквы!
Долго ли, коротко ли, искусник прочел всю надпись и
записал её содержание. «Доброе стекло в трактире Бишопа на чёртовом
стуле двадцать один градус тринадцать минут на норд-норд-ост по главному
суку седьмая ветка восточная сторона стреляй из левого глаза мертвой
головы прямая от дерева через выстрел на пятьдесят футов…»
Мы бы сочли задачу нерешимой. Леграну она не
составила труда. Он нашёл и «трактир Бишопа» — отвесный утес, и «чёртов
стул» — неглубокую нишу на этом утесе. Он сообразил, что «доброе стекло»
— подзорная труба, увидел в нее на суке дерева череп, спустил из глаза
черепа, как отвес, золотого жука, отсчитал нужные футы, и…
«Одних золотых монет было не меньше чем на 450 000
долларов… Было 110 бриллиантов… 18 рубинов… 310 превосходных изумрудов,
двадцать один сапфир и один опал… Мы оценили содержимое нашего сундука в
полтора миллиона долларов…»
Рассказ написан, как это умел делать Эдгар По; если
вам 14 лет, вы проглотите его. Если 44 — прочитаете с большим интересом.
Я прочел его моему внуку-первокласснику — он слушал затаив дыхание.
Писать так о сапфирах и миллионах долларов легко. Но
разве ненамного труднее с такой же увлекательностью рассказывать о… Да
вот о «законе буквы», буквы Е английского языка, которая, вдруг
оказывается, обладает свойством попадаться «чаще других букв» в
английском письме. А значит, и о законах любых других букв?
Но я следил: и эту часть рассказа мой внук слушал,
так же широко раскрыв глаза, так же волнуясь и переживая, как и ту,
приключенческую, с бриллиантами…
Вы можете спросить у меня: «А они правильны, эти
рассуждения Леграна, касающиеся букв? Ведь «Золотой жук» не языковедная
работа: автор-фантаст мог допустить в нём какие угодно предположения и
гипотезы, лишь бы они были занимательны и вели его к цели. Никто не
запретил ему «к былям небылиц без счету прилагать».
Да, читая «Жука», там можно обнаружить и на самом
деле немало чистых выдумок! Но с «законом буквы» все обстоит если и не
«прецизионно», то достаточно точно.
Что, если попробовать произвести для русского языка
такие же подсчеты, которые, будучи произведены некогда в Англии, дали в
руки Леграну и отправной путь его расшифровки, и его полтора миллиона
долларов?
Конечно, можно прямо полезть в справочники и выудить
оттуда нужные данные. Но мне захотелось предварительно, на ваших
глазах, уважаемые читатели, так же как когда-то я и мой соавтор в нашем
романе «Запах лимона» зашифровывали таинственную записку, так же как
Легран в «Золотом жуке» расшифровывал старую надпись на клочке кожи, —
так же произвести для начала опыт таких подсчетов «своими руками».
Я сделал эксперимент, который, собственно, может
повторить каждый из вас. Я взял пять фрагментов из совершенно
неравноценных друг другу произведений пяти непохожих друг на друга,
живших в разные времена, обладавших разной мерой таланта авторов.
Писателей-беллетристов.
Я выбрал авторов не по моим личным склонностям: так в беспорядке лежали друг на друге пять книг на столе у моего сына.
Это оказались Чехов, раскрытый на «Бабьем царстве»,
Гарин-Михайловский — «Студенты», Куприн — «Белый пудель», Мамин-Сибиряк,
в котором оставленный кем-то разрезательный ножик указывал на рассказ
«В камнях», и, наконец, сборник научно-фантастических рассказов
Лениздата «Тайна всех тайн», в котором помещен мой рассказ «Эн-два-о,
плюс икс дважды».
Никаких возможностей сравнения, ни малейшей нарочитости в выборе; объективность подсчетов гарантирована.
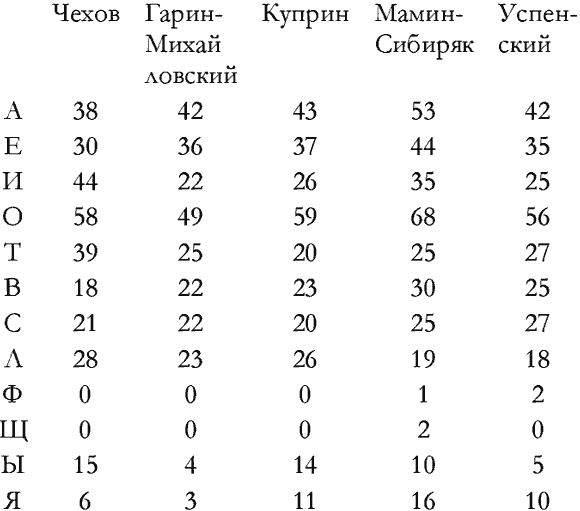
Я решил у всех этих авторов рассмотреть по 12 первых
строк их указанных произведений: еще объективнее; не по выбору, а кто с
чего начал!
Шрифты и форматы книг были, конечно, неодинаковыми,
но при беглом анализе выяснилось, что в этой дюжине строк всюду
укладывалось что-то около 460–500 знаков.
Не пытаясь представить тут перед вами исчерпывающие
данные по всем буквам азбуки, я свел в табличку только штук восемь
наиболее часто встречающихся на письме букв, а к ним добавил еще
четверку тех азбучных нелюдимов, которые обитают в самом конце алфавита и
попадаются много реже других.
Любопытная табличка! За малым исключением, числа
попаданий той или другой буквы в данные 12 строк текста очень близки
друг к другу, несмотря на всяческую несхожесть авторов. Буква О
вышла на первое место и у Чехова, написавшего «Бабье царство» в
подмосковном Мелихове в 1893 году, и у меня, писавшего свой рассказ
почти через 60 лет после этого в послеблокадном Ленинграде. Нет никакой
возможности предположить между нами какой-либо сговор или случайное
совпадение: там 58 О, здесь 56 О. Это тем более немыслимо,
что и у инженера-путейца Гарина-Михайловского, и у поповича
Мамина-Сибиряка, и у Куприна — у всех у них в двенадцати строчках буква О повторялась чаще других букв — 49, 68, 59 раз. За О поспевает А
— и поспевает примерно в одном темпе у всех пятерых авторов.
Мамин-Сибиряк почему-то вырвался вперед — вот это как раз особый случай,
требующий специальных разысканий, почему у него настолько больше А?
Больше «чего»? Больше нормы? Так, значит, есть
«норма», по которой каждому звуку положено зазвучать в нашей речи,
каждой букве «встать в строку» рядом с другими? Может быть, это
определяется случайностью?
В какой-то степени да. Куприн начал «Белого пуделя»
пейзажным кусочком, описанием Крыма. В этом описании, естественно,
оказалось довольно много прилагательных с их характерными окончаниями
«-ый». Вот вам и пять-шесть лишних возможностей для появления буквы Ы. Или, например, естественно, что у трёх авторов из пяти в их отрывках не обнаружилось Ф. После «Фу»-истории» мы понимаем, в чем тут дело: закономерность! А вот почему у меня эта редкость вдруг обнаружилась?
Это чистая случайность. Повесть «Эн-два-о»
начинается со сценки экзамена: студентка хочет получить зачёт у
«профессора». Получай она его у доцента, и «эф» исчезло бы бесследно.
Но в связи с этим мне вспомнился один интересный
экспонат, который в 1930-х годах демонстрировался в Ленинградском Доме
занимательной науки.
То была доска с бортиками, по этим бортикам
застеклённая и закруглённая в верхней части своей. С самого верха сквозь
плоскую воронку можно было под стекло на наклонно стоящую доску сыпать
пшено или перловую крупу. По всей длине доски, снизу доверху, в неё были
набиты, как в детской игре «китайский бильярд», в шахматном порядке
гвоздики. Каждое падающее сверху зёрнышко на своем пути вниз ударялось
об один гвоздик, отскакивало к другому, седьмому, пятнадцатому. Первая
сотня крупинок ложилась у нижней кромки прибора в полном беспорядке.
Но если вы всыпали 100 граммов крупы, уже
обнаруживалось, что больше ее зерен обязательно собирается на середине
нижнего края, меньше — к бокам. Средняя выпуклость росла, росла, и когда
весь выданный вам на руки мешочек с крупой был израсходован, она на
поле доски укладывалась точь-в-точь по одной, уже заранее намеченной там
красной краской линии, по статистической кривой. Было совершенно
безразлично, быстро или медленно сыпали вы крупу, всю сразу или
отдельными порциями — беспорядочный «крупопад» образовывал внизу очень
«упорядоченную фигуру». Один школьник, долго дивившийся на этот феномен,
в конце концов чрезвычайно точно сформулировал его сущность: «Странно…
Крупинки падают в беспорядке, а ложатся в порядке…»
Нечто аналогичное этому наблюдается и в языке — в потоке звуков и в распределении букв.
В те времена, когда в Доме занимательной науки
производился этот опыт по статистике, никто из языковедов еще не
собирался применять статистику к языку и его явлениям; во всяком случае,
если такие исследования кое-кем и производились, то в самых скромных
масштабах.
С тех пор прошло три с половиной десятилетия, и положение переменилось до чрезвычайности.
Я беру книгу. Она называется «Основы языковедения». Автор — Ю. Степанов, издательство «Просвещение», 1966 год.
«Простейший лингвистический вопрос, разрешить
который помогает математика, — пишет автор, — частота фонем в речевой
цепи… Если, — продолжает он, — для упрощения принять, что каждая буква
русского алфавита обозначает фонему, то…»
Дальше он представляет частоту букв в таблице, а из
этой таблицы выводит, что в любом русском тексте на тысячу наугад
выбранных в речевой цепи букв и пробелов между буквами приходится в
среднем — 90 О, 62 А, 2 Ф… и так далее.
Возьмите сравните с теми результатами, которые дали
нам наши кустарные, не претендовавшие ни на какую точность подсчеты, и
вы увидите, что в общем-то мы попали при своих попытках довольно близко
«к яблочку мишени». И у нас на первое место попала буква О, на второе — Л, а буква Ф оказалась фактически почти не присутствующей в тексте «залётной пташкой».
Прошло, как я уже сказал, лишь немного больше трех
десятилетий с упомянутого мною такого недавнего и уже такого бесконечно
далёкого довоенного времени, но за это время в мире науки произошли
грандиозные перевороты. Возникла, в частности, и совершенно не
существовавшая до войны математическая лингвистика, возникла в другой
области интересно связанная с нею кибернетика, возникли электронные
счётно-решающие устройства и возможность «машинного» перевода…
Благодаря всему этому и вопросы языковедной статистики получили совершенно новое значение и новый аспект.
Теперь уже ставится вопрос о возможности — или
невозможности — «атрибуции», то есть как бы «приписания» какого-либо
литературного памятника, считавшегося до сих пор безымянным, тому или
другому давно усопшему автору — на основании статистического (но,
конечно, во сто раз более сложного, чем тот, что я вам показал) учета и
звуковых, и буквенных, и лексических, и синтаксических, и любых других
элементов текста. При помощи счётных машин стало возможным из сложно
наслоившихся на первоначальную основу древнего произведения — эпоса
Гомера, русских былин — выделять аналитическим путем и основное ядро, и
последующие наслоения…
| 
 УЧИТЕЛЬ СЛОВЕСНОСТИ
УЧИТЕЛЬ СЛОВЕСНОСТИ